快速开始
本指南将帮助你快速部署并运行 Closed-LLM-Vtuber 项目。
本指南部署的配置为 Ollama + sherpa-onnx-asr (SenseVoiceSmall) + edge_tts。如需深入定制,请参考用户指南的相关章节。
如果用 OpenAI Compatible 代替 Ollama,用 groq_whisper_asr 代替 sherpa-onnx-asr (SenseVoiceSmall),那么只需配置 API Key 即可使用,无需下载模型文件,也可以跳过对本地 GPU 的配置。
本项目只推荐使用 Chrome 浏览器。已知 Edge、Safari 等浏览器都存在不同的问题。
如果你位于中国大陆,建议你开启代理后再部署和使用本项目,确保能顺利下载所有资源。
如果你遇到开启代理后本地服务 (ollama、gptsovits) 无法访问,但关闭代理后就能访问的问题。请你确保你的代理绕过本地地址 (localhost),或者在所有资源下载完毕后关闭代理再运行本项目。更多信息参考 设置代理绕过 。
Groq Whisper API、OpenAI API 等国外大模型/推理平台 API 一般无法使用香港地区的代理。
如果你更喜欢 Electron 应用 (窗口模式 + 桌宠模式),可以从 Closed-LLM-Vtuber-Web Releases 下载对应平台 Electron 客户端,可以在后端服务运行的前提下直接使用。但你有可能会遇到因为没有签名验证而导致的安全警告,具体情况和解决方案请查看 模式介绍
有关前端的更多信息,请参考 前端指南
设备要求
最低要求
本项目的各个组件 (ASR, LLM, TTS) 都可以选用 API,你可以把想要在本地运行的组件放在本地,本地跑不动的用 API。
因此,本项目的最低设备要求:
- 电脑
- 树莓派也行
本地运行的推荐设备要求
- M 系列芯片的 mac
- Nvidia GPU
- 比较新的 AMD GPU (支持 ROCm 的话会很棒)
- 别的 GPU
- 或是一个强大到,可以代替 GPU 的 CPU。
本项目支持多种不同的语音识别(ASR),大语言模型(LLM),以及语音合成(TTS) 的后端。请根据你的硬件条件量力而行。如果发现运行速度太慢,请选择小一些的模型或者使用 API。
对于本快速开始文档选择的组件,你需要一个速度正常的 CPU (ASR),一个 Ollama 支持的 GPU (LLM),以及网路链接 (TTS)。
环境准备
安装 Git
- macOS
- Linux
# 如果没有安装 Homebrew,请先运行这个命令进行安装,或者参考 https://brew.sh/zh-cn/ 进行安装
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 安装 Git
brew install git
# Ubuntu/Debian
sudo apt install git
# CentOS/RHEL
sudo dnf install git
安装 FFmpeg
FFmpeg 是必需的依赖项。没有 FFmpeg 会导致找不到音频文件的错误。
- macOS
- Linux
# 如果没有安装 Homebrew,请先运行这个命令进行安装,或者参考 https://brew.sh/zh-cn/ 进行安装
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 安装 ffmpeg
brew install ffmpeg
# Ubuntu/Debian
sudo apt install ffmpeg
# CentOS/RHEL
sudo dnf install ffmpeg
检查 ffmpeg 已经成功安装
在命令行中运行
ffmpeg -version
如果出现类似
ffmpeg version 7.1 Copyright (c) 2000-2024 the FFmpeg developers
...(后面一大串文字)
的文字,说明你安装成功了。
NVIDIA GPU 支持
如果你有 NVIDIA 显卡并希望使用 GPU 运行本地模型,你需要:
- 安装 NVIDIA 显卡驱动
- 安装 CUDA Toolkit (推荐 11.8 或更高版本)
- 安装对应版本的 cuDNN
验证安装:
- 检查驱动安装:
nvidia-smi
- 检查 CUDA 安装:
nvcc --version
Python 环境管理
从 v1.0.0 版本开始,我们推荐使用 uv 作为依赖管理工具。
如果你更希望使用 conda 或 venv,也可以使用这些工具。项目自v1.2.0 起完全兼容标准的 pip 安装方式。
关于 pip 与 conda 的指南与注意事项
Details
uv 是这个项目的依赖管理工具,我推荐使用 uv。
conda,pip,以及其他的依赖管理工具也可以用,但我们不会测试这些工具,也不会回答这些工具产生的问题 (因为我们 v1.0.0 版本之前用的是 conda,问 python 相关问题的人真的好多啊呱!)。
如果你一定要用,非用不可,请在使用这些工具时重点关注 Python 版本,虚拟环境使用的 Python 执行档等问题,我们在迁移到 uv 之前有很多,很多人遇到了各种各样的问题。
确保你的 Python 版本 >= 3.10, < 3.13。我不确定当前版本与 3.13 的兼容性,你可以试试。
使用 pip 安装项目依赖
(项目版本
v1.2.0添加)
pip install -r requirements.txt
- 这个
requirements.txt是根据pyproject.toml文件自动生成出来的,可能会把依赖绑的比较紧。如果出现问题,可以参考pyproject.toml中声明的依赖版本,自行松绑。亦或是改用 uv 或其他支持以pyproject.toml声明依赖的工具。
或是
pip install -e .
- 这个命令会用 pyproject.toml 文件安装依赖,但会把项目本身也一起安装到环境中,我感觉项目更新时有可能会出问题,但我不确定。
然后运行项目
python run_server.py
之后文档中出现的任何 uv add, uv remove 命令,可以直接代替换成 pip install, pip uninstall 等命令。
conda
- 在当前目录下,创建 conda 环境
conda create -p "./.conda" python=3.10.6
- 激活这个 conda 环境
conda activate ./.conda
- 用 pip 安装项目依赖
pip install -r requirements.txt
- 运行项目
python run_server.py
之后文档中出现的任何 uv add, uv remove 命令,可以直接代替换成 pip install, pip uninstall 等命令。
- macOS/Linux
# 方法 1: curl
curl -LsSf https://astral.sh/uv/install.sh | sh
# 或者运行 wget -qO- https://astral.sh/uv/install.sh | sh 如果你的电脑上不存在 curl
# 方法 2: homebrew (如果已安装)
brew install uv
# 重要:安装完成后请运行以下命令重新加载配置文件,或者重启命令行 / IDE
source ~/.bashrc # 如果使用 bash
# 或
source ~/.zshrc # 如果使用 zsh
对于 curl 或 wget,安装完 uv 后需要重启命令行 / IDE 或重新加载配置文件
更多 uv 安装方法参考:Installing uv
部署指南
1. 获取项目代码
我们需要下载项目代码。有两种方法获取项目代码。
请把项目放在一个合适的位置,路径中不要包含中文。
- 下载稳定的 release 包
- Git 命令拉取
- 不要从 Code 按钮下载 zip
从项目的 Release 页面,下载长得像 Closed-LLM-Vtuber-v1.x.x.zip 的 zip 文件。
注意,是 Release 页面,不是项目主页上面那个 Code 按钮的 "Download ZIP" 选项。请不要用 "Download ZIP" 按钮下载项目代码。
如果你想要使用桌宠模式或是桌面版本,你可以顺手再下载以 closed-llm-vtuber-electron 开头的文件。macOS 用户下载 dmg 文件。这个是桌面版本的客户端。之后等后端配置完成并启动之后,这个 electron 版前端可以启动桌宠模式。
使用 git 拉取时,请确保网络畅通。中国大陆用户可能需要开启代理。
git clone 命令后面必须加上 --recursive flag。
这是因为自 v1.0.0 开始,前端代码 (用户界面) 已被拆分到独立仓库中。我们建立了构建流程,通过 git submodule 将前端代码链接到主仓库的 frontend 目录下,因此在克隆仓库时要添加 --recursive 的 flag,否则会缺失前端代码,造成 浏览器显示 Detail Not Found 的错误。
# 克隆仓库 / 下载最新的 Github Release
git clone https://github.com/Closed-LLM-Vtuber/Closed-LLM-Vtuber --recursive
# 进入项目目录
cd Closed-LLM-Vtuber
如果你想要使用桌宠模式或是桌面版本,你可以前往Closed-LLM-Vtuber-Web 的 Release 页面 顺手再下载以 closed-llm-vtuber-electron 开头的文件。macOS 用户下载 dmg 文件。这个是桌面版本的客户端。之后等后端配置完成并启动之后,这个 electron 版前端可以启动桌宠模式。
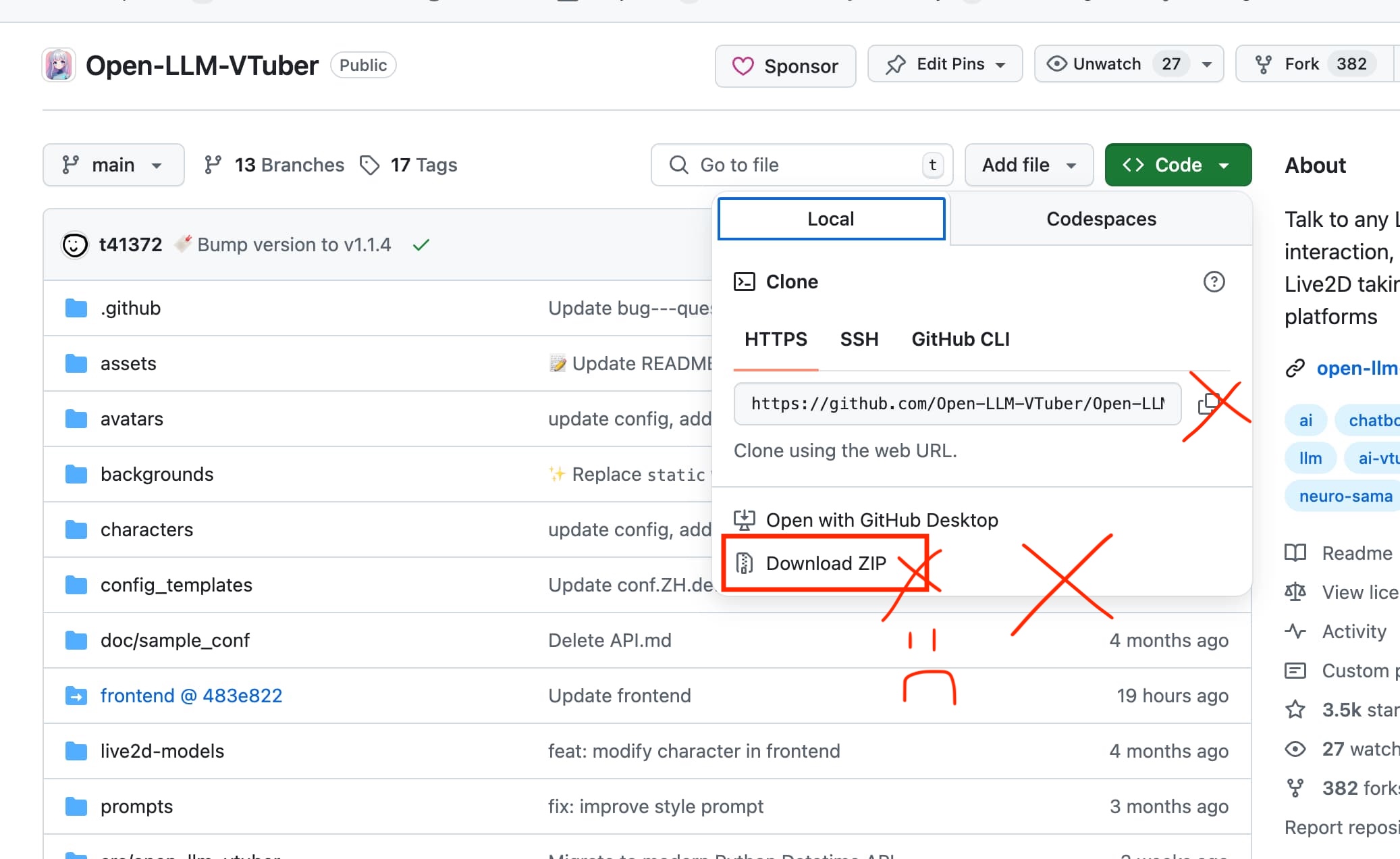
请 不要 从 GitHub 主页上,那个绿色的 "Code" 按钮那边,下载 Zip 文件,或是直接用那边提供的克隆命令,获取项目代码。
为什么不能从 Code 按钮下载 Zip 文件?
- 从 Code 按钮中获取的 Zip 文件 不包含 Git 信息。这是 Github 自己生成的,我没法控制。
- 本项目前端由 submodule 链接,如果你从这个按钮下载 Zip 文件,你会拿不到前端代码,导致 浏览器显示 Detail Not Found 的错误
- 本项目更新机制依赖 Git,因此缺失 Git 信息会导致你无法使用更新功能。
2. 安装项目依赖
⚠️ 如果你不在中国大陆境内,没有必要使用镜像源。
内地用户可以配置 Python 与 pip 的镜像源,提高下载速度。此处我们配置阿里镜像。
Details
请在项目目录下的 pyproject.toml 文件底部添加下面内容。
[[tool.uv.index]]
url = "https://mirrors.aliyun.com/pypi/simple"
default = true
一些其他镜像源 (修改上面的 url 部分)
- 腾讯镜像: https://mirrors.cloud.tencent.com/pypi/simple/
- 中科大镜像: https://pypi.mirrors.ustc.edu.cn/simple
- 清华镜像(安装我们项目好像有点问题): https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
- 华为镜像: https://repo.huaweicloud.com/repository/pypi/simple
- 百度镜像: https://mirror.baidu.com/pypi/simple
有些镜像源有时候可能会不稳定,如果出现问题,可以换一个镜像源试试。 使用镜像源的时候不要打开代理。
确认 uv 已正确安装:
uv --version
创建环境并安装依赖:
# 确保你在项目根目录下运行这个命令
uv sync
# 这个命令将创建一个 `.venv` 虚拟环境,
内地用户如果在此处出错,可以尝试开启代理后重新运行此命令。
接着,我们运行一下主程序来生成预设的配置文件。
uv run run_server.py
然后按下 Ctrl + C 退出程序。
v1.1.0 版本开始,conf.yaml 文件可能不会自动出现在项目目录下。请复制 config_templates 目录下的 conf.default.yaml 或 conf.ZH.default.yaml 文件到项目根目录并重命名为 conf.yaml。
或者,你也可以通过运行主程序 uv run run_server.py 并使用 Ctrl + C 退出程序来生成配置文件(不推荐使用这个方法)。请注意,退出操作需要及时执行,否则程序会开始下载模型文件(此刻退出可能会导致下次无法启动,解决方案为删除 models/ 下的全部文件)。
3. 配置 LLM
本项目默认使用 Moonshot AI 的 Kimi 模型(kimi-k2-turbo-preview)。Kimi 支持超长上下文窗口,具备强大的性能和高速输出能力。
项目使用 OpenAI 兼容的 API 格式,支持所有兼容 OpenAI Chat Completion 格式的 API 端点。这包括:
- Kimi(默认,Moonshot AI)
- Ollama(本地运行)
- OpenAI 官方 API
- LM Studio(类似 Ollama,使用更简单)
- vLLM(性能更好,配置较复杂)
- 以及其他支持 OpenAI 格式的 API 提供商
更多信息请参考LLM 配置指南。
示例:使用 Ollama(本地运行)
如果你想在本地运行模型,可以使用 Ollama:
- 从 Ollama 官网 下载并安装
- 验证安装:
ollama --version
- 下载并运行模型(以
qwen2.5:latest为例):
ollama run qwen2.5:latest
# 运行成功后,你就可以直接跟 qwen2.5:latest 对话了
# 可以先退出聊天界面 (Ctrl/Command + D),但一定不要关闭命令行
- 查看已安装的模型:
ollama list
# NAME ID SIZE MODIFIED
# qwen2.5:latest 845dbda0ea48 4.7 GB 2 minutes ago
寻找模型名时,请使用 ollama list 命令,查看 ollama 中已下载的模型,并将模型名称直接复制粘贴到 model 选项下,避免模型名打错,全形冒号,空格之类的问题。
选择模型时,请考虑你的显存容量与GPU算力。如果模型文件大小大于显存容量,模型会被迫使用 CPU 运算,速度极慢。另外,模型参数量越小,对话延迟越小。如果你希望降低对话延迟,请选择一个参数量较低的模型。
修改配置文件
如果你的项目目录下没有 conf.yaml 文件,请运行一次项目主程序 uv run run_server.py,生成配置文件,然后退出。
编辑 conf.yaml:
- 确保
basic_memory_agent下的llm_provider设置为openai_compatible_llm(这是默认值) - 调整
llm_configs选项下的openai_compatible_llm下的设置:
使用 Kimi(默认配置,推荐):
openai_compatible_llm:
base_url: "https://api.moonshot.cn/v1" # Moonshot AI API 端点
llm_api_key: "your-moonshot-api-key" # 你的 Moonshot API 密钥
model: "kimi-k2-turbo-preview" # 使用的模型
temperature: 1.0 # 控制回答随机性,越高越随机 (0~2)
- 访问 Moonshot AI 平台
- 注册并登录账号
- 在控制台中创建 API 密钥
- 将 API 密钥填入
llm_api_key字段
更多信息请参考 Moonshot AI 官方文档。
使用 Ollama(本地运行):
openai_compatible_llm:
base_url: "http://localhost:11434/v1" # Ollama 的 API 端点
model: "qwen2.5:latest" # ollama list 得到的模型名称
temperature: 0.7 # 控制回答随机性,越高越随机 (0~1)
使用 OpenAI 官方 API:
openai_compatible_llm:
base_url: "https://api.openai.com/v1"
llm_api_key: "sk-..." # 你的 OpenAI API 密钥
model: "gpt-4o"
temperature: 1.0
使用其他兼容 OpenAI 格式的 API:
openai_compatible_llm:
base_url: "https://api.example.com/v1" # 替换为你的 API 端点
llm_api_key: "your-api-key" # 如果需要的话
model: "your-model-name"
temperature: 1.0
关于配置文件的详细说明,可以参考 用户指南/配置文件。
4. 配置其他模块
本项目 conf.yaml 默认配置中使用了 sherpa-onnx-asr (SenseVoiceSmall) 和 edgeTTS,你可以不用进行修改。
或者你可以参考 ASR 配置指南 和 TTS 配置指南 进行修改。
5. 启动项目
运行后端服务:
uv run run_server.py
# 第一次运行可能会下载一些模型,导致等待时间较久。
运行成功后,浏览器访问 http://localhost:12393 即可打开 Web 界面。
如果你更倾向于使用 Electron 应用(窗口模式 + 桌宠模式),可以从 Closed-LLM-Vtuber-Web Releases 下载对应平台的 Electron 客户端。该客户端可在后端服务运行时直接使用,你可能会遇到安全警告(由于未进行代码签名)——具体说明和解决方案请查阅模式介绍。
关于前端的更多信息,请查阅 前端使用指南
下一步
- 常见问题
- 长期记忆 (Letta)
- 桌宠模式
- 修改 AI 角色的设定(提示词)
- 修改 Live2D 模型
- 修改 LLM 大语言模型
- 修改 TTS 模型 (AI 的声音模型)
- 修改 ASR 模型 (语音识别模型)
- 参与讨论,加入社区
- 参与开发
长期记忆?
1.2.0 版本加入了基于 Letta (也就是 MemGPT) 的长期记忆实现 (PR #179),虽然回答延迟会增加,但能实现效果较好的长期记忆。
如果你的项目目录下没有 conf.yaml 文件
v1.1.0 版本开始,conf.yaml 文件可能不会自动出现在项目目录下。请运行一次项目主程序 uv run run_server.py 生成配置文件。
如果遇到 Error calling the chat endpoint... 错误,请检查:
-
http://localhost:11434/ 是否能正常访问,如果不能,可能是因为
ollama run没有运行成功,或者运行成功后命令行被关闭了。 -
报错中提示
Model not found, try pulling it...,请使用ollama list查看已安装的模型名称,确保配置文件中的模型名称与列表中的完全一致。 -
如果你的代理软件没有绕过本地地址,会导致 Ollama 无法连接。尝试临时关闭代理,或参考前文设置代理绕过本地地址。
关于这个问题,我们在 常见问题 -> #遇到-error-calling-the-chat-endpoint-错误怎么办 中有详细解释。